Thin content: jak znaleźć bezwartościowe podstrony w swoim serwisie?
Definicja „thin content” jest zaskakująco pojemna, choć generalnie sprowadza się do opisania stron bez wartości dla użytkowników, albo raczej dla robotów indeksujących wyszukiwarek. Niemal każdy serwis, jaki poddałem analizie optymalizacji, zawierał podstrony które nie powinny być indeksowane przez wyszukiwarki. Problem wynika zwykle nie tyle ze złej woli, czy niechlujstwa, co samej specyfiki popularnych systemów CMS, generujących w zautomatyzowany sposób dodatkowych podstron, które niepotrzebnie zajmują czas pracy robota (tzw „crawl budget„). Jak te podstrony zidentyfikować i co z nimi zrobić?

Czym są strony o niskiej/zerowej wartości?
Na potrzeby publikacji pominę przypadki masowego generowania stron o niskiej wartości w sposób świadomy (jeśli wiesz co robisz, najpewniej znasz też konsekwencje).
Strony o niskiej wartości – w kontekście samych wyszukiwarek internetowych – to takie, które:
– zawierają bardzo mało unikalnej treści (poza elementami stałymi tj. menu nawigacyjne, czy informacje w stopce),
– zostały wygenerowane w sposób automatyczny na podstawie treści z innych podstron serwisu (np. strony tagów, bez dodatkowego opisu),
– potencjalnie też strony o minimalnej lub wręcz zerowej liczbie wizyt
Zagrożenia, jakie niesie duża ilość „thin content”
Popularne systemy CMS generują mnóstwo dodatkowych podstron – zbiory tagów, sortowania, wewnętrzne wyniki wyszukiwania, itp. O ile dany serwis będzie liczyć łącznie kilkadziesiąt podstron, z których większość będzie jednak mieć istotną wartość i generować ruch z wyszukiwarek, problem w zasadzie można pominąć. Jednak większe serwisy, gdzie podstron może być znacznie więcej powinny aktywnie dbać o indeksowanie przez wyszukiwarki nowych i aktualizowanych zasobów w swoich domenach. W skrajnych sytuacjach robot może sobie „wygenerować” tysiące podstron z wewnętrznymi wynikami wyszukiwania, co – nawet w przypadku gdyby nie zostały one dodane do indeksu – zabierze znaczą część czasu jaki Google przeznaczyło na indeksowanie zasobów danej domeny. Tym sposobem, zamiast pobierać np. nowe produkty dodane w sklepie, robot opóźni ich indeksację, tracąc czas na przemierzanie bezwartościowych podstron.
Drugi problem to algorytm „Google Panda”, który w przypadku znalezieniu dużej liczby podstron o niskiej wartości, może stać się przyczyną mniejszego zasięgu całego serwisu.
Jak odnaleźć podstrony zawierające mało treści?
Chyba wszystkie aktualne narzędzia do analiz SEO pozwalają w pewien sposób wychwycić podstrony, które mają relatywnie małą objętość treści, lub generują wewnętrzne duplikaty.
Przykładowe badanie wykonane narzędziem SiteBulb (jest wersja testowa) pozwala wstępnie ustalić potencjalnych „podejrzanych” w oparciu o dane z raportu „On Page”: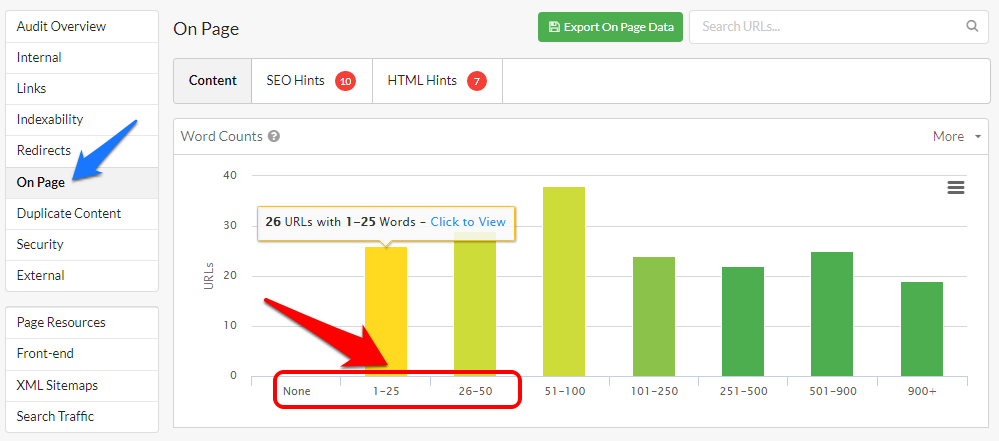
Interesują nas kolumny z lewej strony – począwszy od tej z zupełnym brakiem treści, optymalnie do 50 słów (zależnie od charakteru serwisu można skupić się na pierwszych 2, lub nawet 4 zbiorach – do 100 słów).
Klikając w wybraną kolumnę dostaniemy szczegółowy raport prezentujący adresy URL w zbiorze oraz ich najważniejsze parametry. Dobrze jest wstępnie ograniczyć listę do adresów, które nie mają zablokowanej indeksacji.
Można to łatwo zrobić dodają filtr zgodny, jak prezentuję na poniższym zrzucie:
Zapisz się do newslettera
i pobierz checklistę
wdrożeniową GA4
Dzięki niej prawidłowo wdrożysz Google
Analytics 4 na swojej stronie!

Poniżej widać same dane, wraz z liczbą słów na każdej z podstron.
Sitebulb jest sprytnym narzędziem i stara się określić (z całkiem dobrą skutecznością!) które elementy dotyczą np. nawigacji czy powtarzalnych elementów, a które są rzeczywistą unikalną treścią. Stąd na powyższym obrazie raport prezentuje adresy, gdzie podstrony mają łącznie 700-800 słów, ale tylko kilka słów w samej treści w danym adresie URL. To bardzo interesująca funkcja, która wyróżnia Sitebulb na tle konkurencyjnych rozwiązań i znacząco ułatwia wyszukiwanie podstron z małą ilością unikalnej treści. Tego nie zrobicie Screaming Frogiem ;)
Przeglądając kolejne adresy w raporcie można samodzielnie ocenić, czy strona nie powstała w wyniku błędu i czy powinna znaleźć się w indeksach wyszukiwarek.
Z przykładowego raportu możemy trafić np. na taką podstronę, o której istnieniu nikt z administratorów nie miał pojęcia: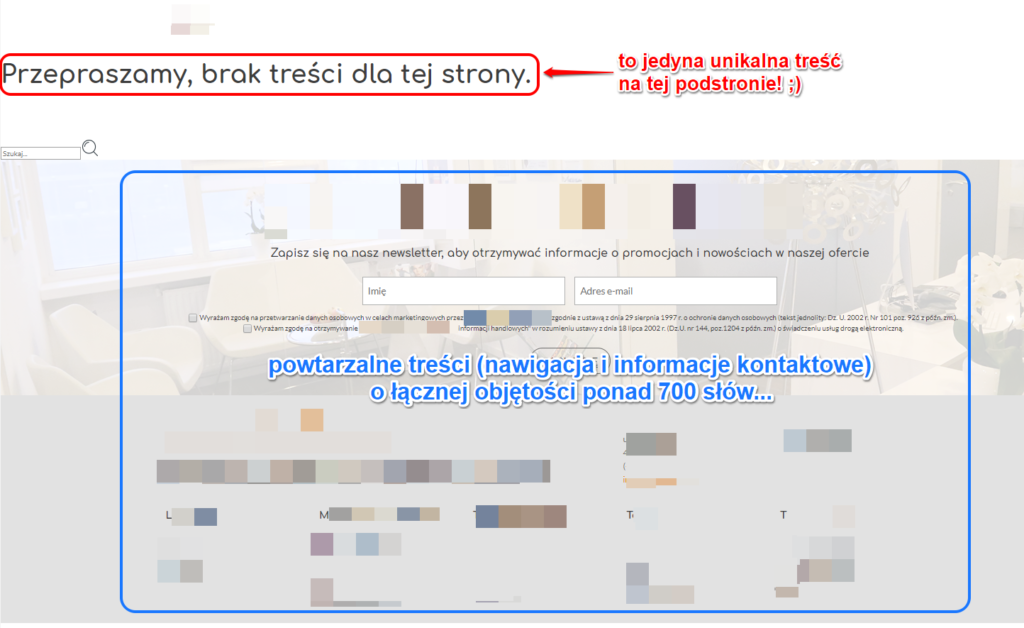
Oczywiście pojedynczy adres tego typu nie stanowi problemu, jeśli jednak podobnych stron generują się setki, to mogą już istotnie zająć czas robota indeksującego i narazić na obniżoną całościową ocenę jakości treści.
Raport dla podstron nie generujących ruchu
Drugie – równie istotne, choć trudniejsze w ocenie badanie pod kątem oceny jakości treści, opiera się o ruch organiczny kierowany na podstrony. A raczej jego brak.
Ponownie wykorzystam tutaj Sitebulb, choć nie jest to już funkcja dla tego narzędzia.
Tym razem wykorzystam raport „Search traffic”. Raport ten wymaga połączenia z API Google Analytics i/lub Google Search Console. Ogólną skalę problemu prezentuje wykres podsumowujący raport:
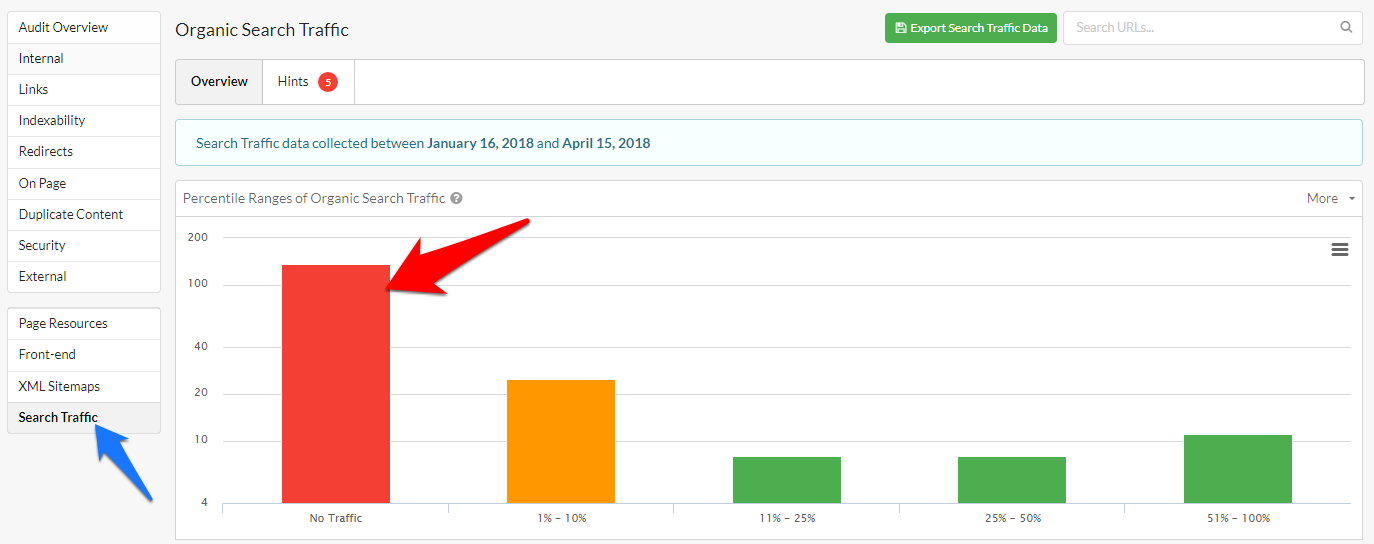
A kliknięcie w samą kolumnę „No traffic” pozwoli przejrzeć adresy, które w zadanym okresie czasu nie wygenerowały żadnych wizyt z kanału organicznego:
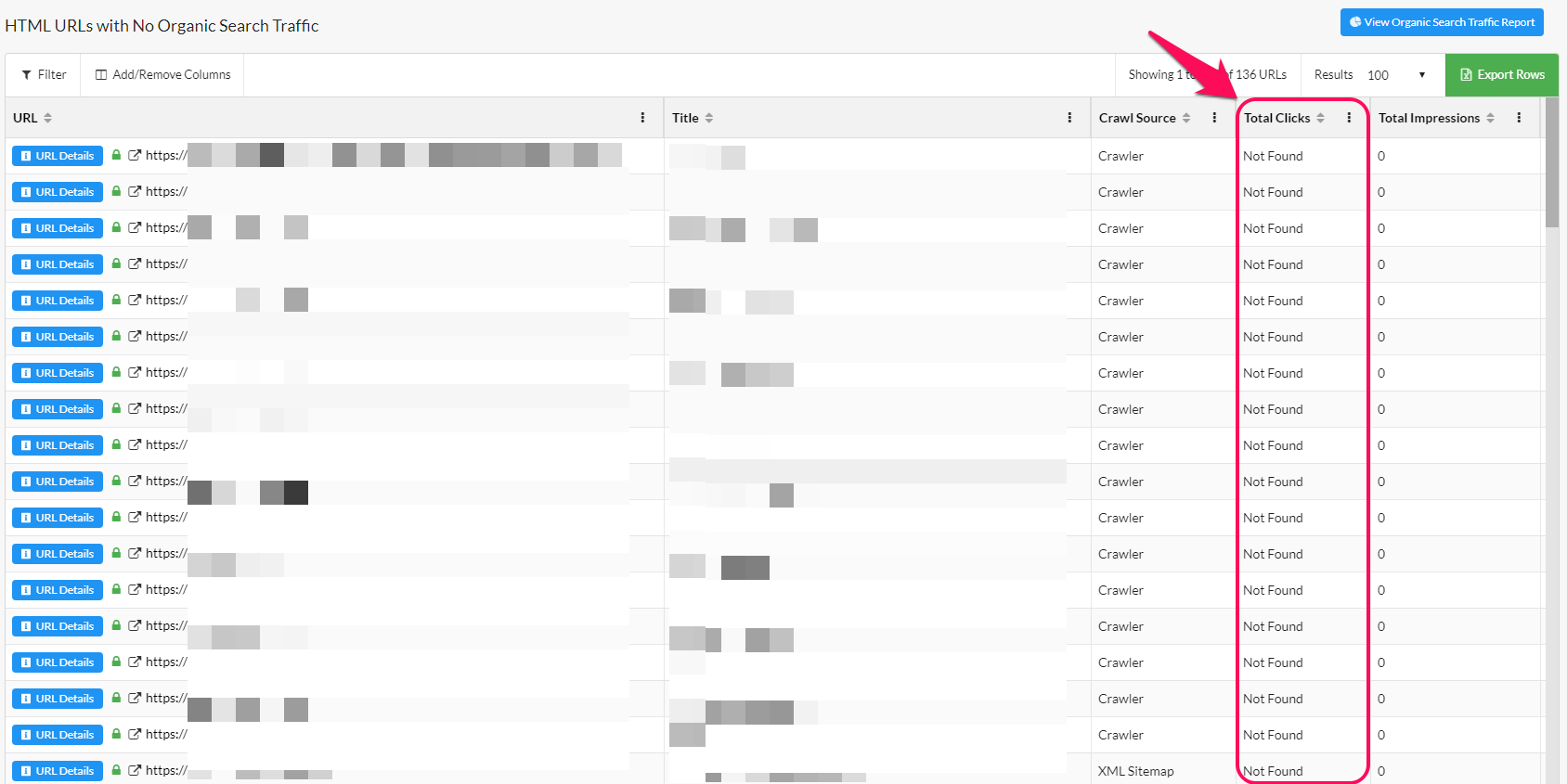
Podstrony takie – szczególnie jeśli zawierają małą objętość treści, lub też wiemy, że treść ta jest generowana w sposób zautomatyzowany, będą dobrymi kandydatami do rozważenia blokady indeksacji.
Zanim jednak zaczniesz masowo dodawać „noindex” do takich podstron upewnij się, że:
– okres czasu dla danych pobranych z API jest odpowiednio długi (optymalnie przynajmniej 3 miesiące) – w przypadku mocno sezonowych treści w małych serwisach, brak ruchu w pewnych okresach czasu może być przecież zjawiskiem naturalnym,
– podstrony istnieją dostatecznie długo, by zdobyć ruch,
– podstrony te zostały w ogóle zaindeksowane przez Google :)
Co zrobić z bezwartościowymi podstronami?
W obu analizowanych przypadkach – przy stwierdzeniu małej objętości unikalnych treści lub braku ruchu organicznego możliwe rozwiązania będą takie same: podstrony takie należy zdecydowanie przebudować (rozbudować), zablokować ich indeksację lub – w przypadku zupełnego braku sensu ich istnienia – całkowicie usunąć (lub ew. przekierować).
Osiągaj wysokie pozycje w wyszukiwarce, które przełożą się na większą sprzedaż.
Praca z taką analizą treści będzie w większych serwisach bardziej czasochłonna niż poprawianie typowych technicznych błędów optymalizacji. Polecam jednak sprawdzać wyrywkowo podejrzane adresy i dążyć do określania całych grup adresów (np. podstron tagów, autorów, itp.), które będą spełniać warunki „bezwartościowości” i bez żalu blokować ich indeksację. Niekiedy będzie to jeden z łatwiejszych sposobów na poprawienie szybkości indeksowania nowych podstron, które nie będą wtedy blokowane przez nieistotne zasoby.
Polecamy również:



O autorze:
Sławomir Borowy