Czym jest crawl budget i jak go zoptymalizować?
Jeżeli publikujesz treści na swojej stronie, na pewno zależy Ci na tym, aby wyszukiwarki w jak najkrótszym czasie do nich dotarły i uwzględniły je w wynikach wyszukiwania. To z kolei pozwoli użytkownikom dotrzeć na wspomnianą stronę, a Tobie pomoże w realizacji założonych celów. Aby było to możliwe, witryna musi być odwiedzana przez roboty wyszukiwarki, za co odpowiedzialny jest crawl budget.

Crawl budget w skrócie
Crawl budget to limit stron i zasobów, które robot wyszukiwarki może odwiedzić i zaindeksować w obrębie jednej domeny w określonym czasie. Crawl budget ustalany jest przez wyszukiwarkę i wskazuje, jak często i w jakim stopniu wyszukiwarka będzie skanowała i indeksowała zasoby danego serwisu. Ilość stron, które będą indeksowane przez roboty wyszukiwarki (crawlery, pająki, Googleboty), określana jest na podstawie dwóch czynników: crawl rate limit i crawl demand.
Crawl rate limit
Crawl rate limit to czynnik określający w jakiej sali Googlebot może skanować stronę w sposób nie wpływający na jej działanie. Wyszukiwarka Google wprowadziła ten limit aby zapobiec przeciążeniom serwerów, na których znajdują się witryny, wywołanym przez zbyt dużą liczbę wysyłanych zapytań w krótkim czasie.
Głównym czynnikiem wpływającym na crawl rate limit jest szybkość strony. Oznacza to, że dla witryn szybciej odpowiadających na zapytania wyszukiwarki limit ten zostanie zwiększony, przez co crawlery będą mogły zaindeksować większą liczbę podstron witryny. Negatywny wpływ na limit ilości adresów URL poddanych indeksacji przy odwiedzinach strony przez crawl Googlebota mają wszelkie błędy, które utrudniają lub uniemożliwiają robotom dotarcie do treści podstron.
Crawl demand
Crawl demand to czynnik definiujący to, jak często roboty indeksujące mają odwiedzać stronę i aktualizować obecne bądź indeksować nowe treści. Zapotrzebowanie na ponowne crawlowanie witryny wyszukiwarka określa między innymi na podstawie jej popularności. Dlatego strony chętnie odwiedzane przez użytkowników i posiadające wartościowe odnośniki zewnętrzne będą częściej indeksowane przez roboty Google.
Oprócz popularności strony, wpływ na crawl demand i indeksowanie w Google ma także aktualność treści znajdujących się w obrębie witryny. Google premiuje w tym kontekście strony, na których treści są często aktualizowane lub w ich obrębie pojawiają się nowe podstrony o wartościowej zawartości. Na częstotliwość crawlowania ma także wpływ typ witryny, dlatego wyszukiwarki częściej będą odwiedzać strony sklepów, w których codziennie pojawiają się nowe produkty, niż sporadycznie aktualizowane statyczne strony firmowe.
Crawl budget i jego wpływ na pozycjonowanie
Sam crawl budget nie jest czynnikiem rankingowym, jednak aby podstrony serwisu mogły walczyć o pozycje w wyszukiwarce, konieczne jest ich uprzednie prawidłowe zaindeksowanie. By wyszukiwarka mogła dotrzeć do wszystkich indeksowalnych podstron w obrębie domeny, należy dostosować witrynę i jej infrastrukturę.
Jak podaje Google na swoim blogu Google Search Central, większość właścicieli stron nie musi się przejmować problemami z crawl budgetem. W przypadku niewielkich serwisów mających np. 100 adresów URL, indeksacja nowych treści nie powinna stanowić problemu. Jednak witryny mające np. 10000 adresów URL znacznie częściej będą miały problemy z prawidłowym kierowaniem Googlebotów, co z kolei będzie powodować problemy z crawl budgetem. Stronami szczególnie narażonymi na problemy z crawl budgetem są duże serwisy, w których adresy generują się automatycznie na podstawie filtracji lub sortowania według parametrów.
Jak zoptymalizować crawl budget:
1. Pozbądź się błędów generowanych przez stronę.
2. Unikaj nadmiernego stosowania Java Scriptu i nieczytelnego dla robotów kodu strony.
3. Maksymalnie skróć wszystkie łańcuchy przekierowań.
4. Zablokuj dostęp robotom do wszystkich podstron o niskiej wartości.
5. Unikaj duplikacji treści.
6. Regularnie aktualizuj mapę strony i usuń z niej adresy, które nie powinny znaleźć się w indeksie wyszukiwania.
7. Zadbaj, aby do każdej kluczowej strony prowadziły linki wewnętrzne.
Narzędzia pozwalające widzieć stronę jak Googlebot
Niestety roboty Google nie widzą strony w taki sposób jak użytkownicy, co jest jedną z przyczyn problemów wpływających na prawidłowe indeksowanie strony. Do lepszego zrozumienia w jaki sposób działają crawlery i sprawdzenia, czy witryna jest dla nich czytelna, można wykorzystać narzędzia pozwalające przeanalizować stronę z perspektywy Googlebota.
Zapisz się do newslettera
i pobierz checklistę
wdrożeniową GA4
Dzięki niej prawidłowo wdrożysz Google
Analytics 4 na swojej stronie!
User-Agent Switcher
Dzięki wtyczce do przeglądarki User-Agent Switcher użytkownik może zmienić tryb przeglądania między innymi na ten pozwalający na przeglądanie sieci jako Googlebot. Wcielając się w robota Google można w łatwy sposób zweryfikować, czy strona jest całkowicie czytelna dla wyszukiwarki oraz czy robot indeksujący ma możliwość dotarcia do każdej z jej podstron.
Google Search Console
Wyszukiwarka w narzędziu Google Search Console pozwala na przyjrzenie się zaindeksowanym podstronom zarówno pod kątem wizualnym, jak i pod kątem pobranego kodu strony.
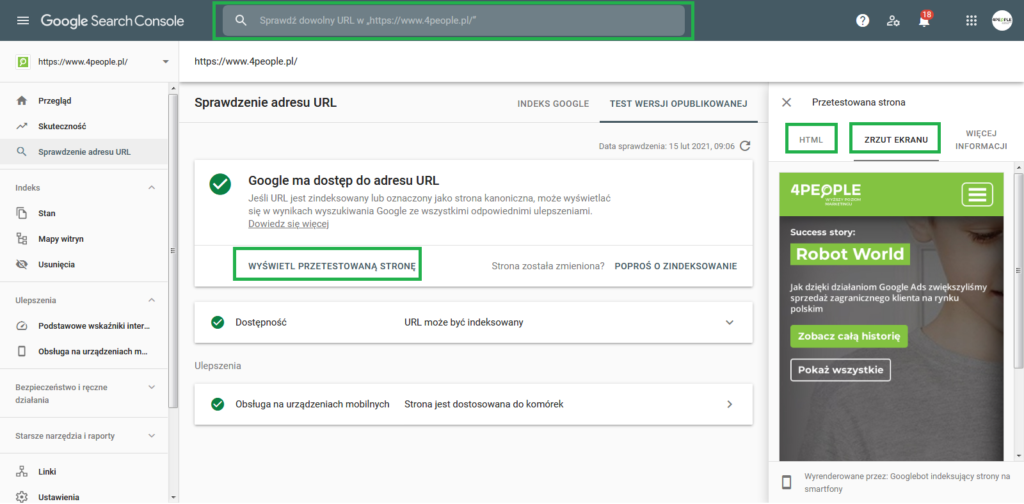
Aby sprawdzić, w jaki sposób Google renderuje konkretną podstronę i czy przy renderowaniu nie pojawiają się błędy, należy wkleić URL wybranej podstrony w pole wyszukiwania w górnej belce. Następnie po przejściu do sekcji “WYŚWIETL PRZETESTOWANĄ STRONĘ” można sprawdzić poprawność renderowania witryny oraz czy wyszukiwarce udało się pobrać jej wszystkie zasoby.
Statystyki indeksowania
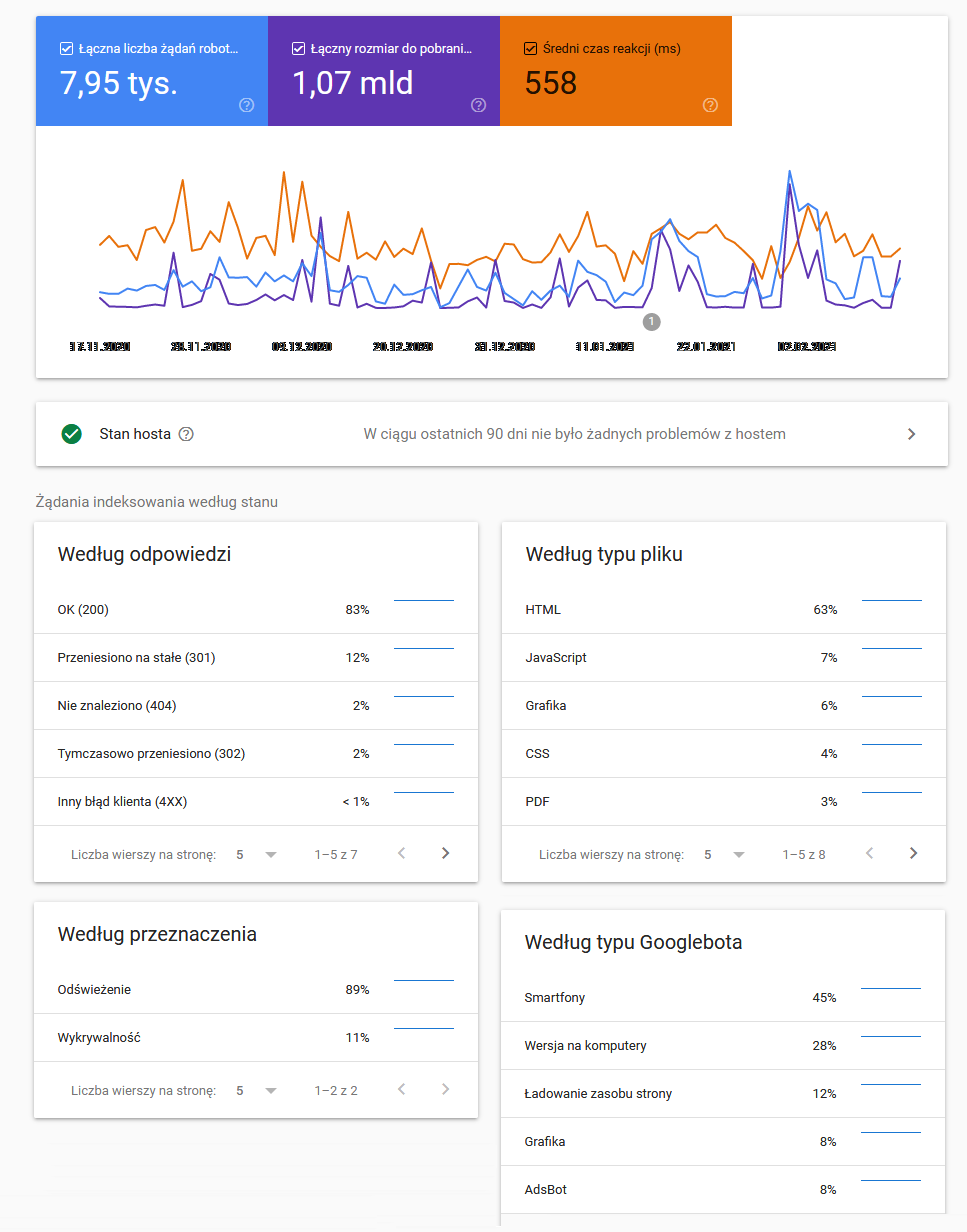
Wiele przydatnych danych w procesie optymalizacji strony pod kątem crawl budgetu znajduje się w raporcie “Statystyki indeksowania” w Google Search Console. Dzięki danym dotyczącym liczby żądań robota indeksującego, rozmiaru pobieranych danych i czasu spędzonego na stronie w ujęciu 3 ostatnich miesięcy, można wnioskować o zmianach dokonywanych przez Google w crawl budget dla danej witryny.
Osiągaj wysokie pozycje w wyszukiwarce, które przełożą się na większą sprzedaż.
W optymalizacji strony pod crawl budget przydatne są także dane dotyczące rodzaju stron, które odwiedza crawl Googlebot. Można na ich podstawie wnioskować, jaka część zasobów przeznaczonych na indeksowanie jest marnowana na odwiedzanie stron błędów lub przeładowywanie łańcuchów przekierowań.
Polecamy również:

O autorze:
Aleksander Foit
